The world has gone crazy for AI. AI discussions are dominating keynotes, product releases, and Twitter threads. But what does building with AI actually look like? I wanted to learn, so I started small and spent a day experimenting.
A simple AI experiment
I needed an experiment that was small enough to be shippable in a day, but large enough to challenge me. I decided to update the recommendation feature on this blog. The previous algorithm suggested the three latest articles. It did the job, but wasn’t too smart. It was the perfect target for my AI experiments. It was simple to understand, but would a deeper understanding of AI to get it done.
Getting familiar with AI
I wanted to create a some POCs (proofs of concept) to help me learn. The first step was to get the OpenAI API running in my project. I kept it simple and asked it to, “tell me a joke”. After following the getting started guide (and some configuration) I got it a response.
“Q: What did the fish say when it hit the wall?
A: Dam!”
–‘text-davinci-003’
By doing this, I learned that requests are made of tokens. Each token is a snippet of text, usually the length of a word. There’s a limit on the number of tokens you can send and receive in each API call. The longer the prompt, the less room for the response. If you set this limit too low, or make the prompt too big, you get incomplete responses.
Proving the Concept
By updating the prompt from, “Tell me a joke”, I could turn it into something useful. I passed a list of article titles and asked for the three most related ones. After some finessing, I landed on the following prompt:
const prompt = `
Given the title of an article is "${article_title}".
Which three articles from the following array of article titles are the most related?
${JSON.stringify(article_titles)}.
Return your answer in the following JSON format:
{ "recommendations": ["one", "two", "three"] }
`
I learned that writing prompts like BDD tests is quite effective. The AI was more likely to understand the question if I laid it out clearly.
To make the result parsable, it was crucial to provide a format. Asking it to, “return the answer in JSON” was not enough. I needed to provide an example response to get a more reliable result. More reliable, but not completely reliable.
Here’s what I got when asking for related articles for “Increase You Focus With Pomodoro”:
{
"recommendations": [
"increase your focus with pomodoro"
"automate your meeting agendas",
"find what makes you productive"
]
}
Though it was obvious in hindsight, the most related article was the article itself. This was easy to fix by filtering it out of the list before passing it up. The POC worked well, but there were a few problems I wanted to address:
1. It wasn’t reliable
Since this was chat-based, the outcome wasn’t reliable.
It worked 80% of the time, but often gave a poor response.
It had a habit of adding extra text around the JSON, making it harder to parse.
Switching from the text-davinci-003 model to the more chat-focused gpt-3.5-turbo model helped, but didn’t completely fix it.
I would need to write a more robust response parser if I were to move this from POC to production-ready code.
2. The recommendations weren’t great
The recommendations were okay, but they were a bit naive. Since I was only sending the titles of the articles, we weren’t giving the AI much data to work with. For example: “Running a Conference” would recommend, “Running the JamStack on GitLab”, instead of the more obvious, “Starting a Meetup”. To get better results, I’d need to give the AI more data.
3. There were too many API calls
The OpenAI API isn’t free. Up to this point I had only spent a few cents, but at scale this could get expensive. Running this for every article—and passing more data per article—would increase costs. I needed to reduce and cache these calls wherever possible.
Using OpenAI Embeddings
After a bit more research into the issues above, I discovered embeddings. Instead of writing a prompt for every article, I could send them all to the embedding endpoint. This would return a multi-dimensional graph with all the articles plotted on it. The closer the points are on the graph, the more related they are.
To understand how embeddings work, we need to simplify what they’re doing.
Imagine all the articles plotted on a standard 2D chart. On each axis is a different topic. There’s “leadership” on one and “engineering” on another. We can plot all the articles on this chart based on how much the content within them relates to each topic. When we look at this chart, we can see the ones that are closer together are more related to each other. The ones that are further apart, will have less in common.
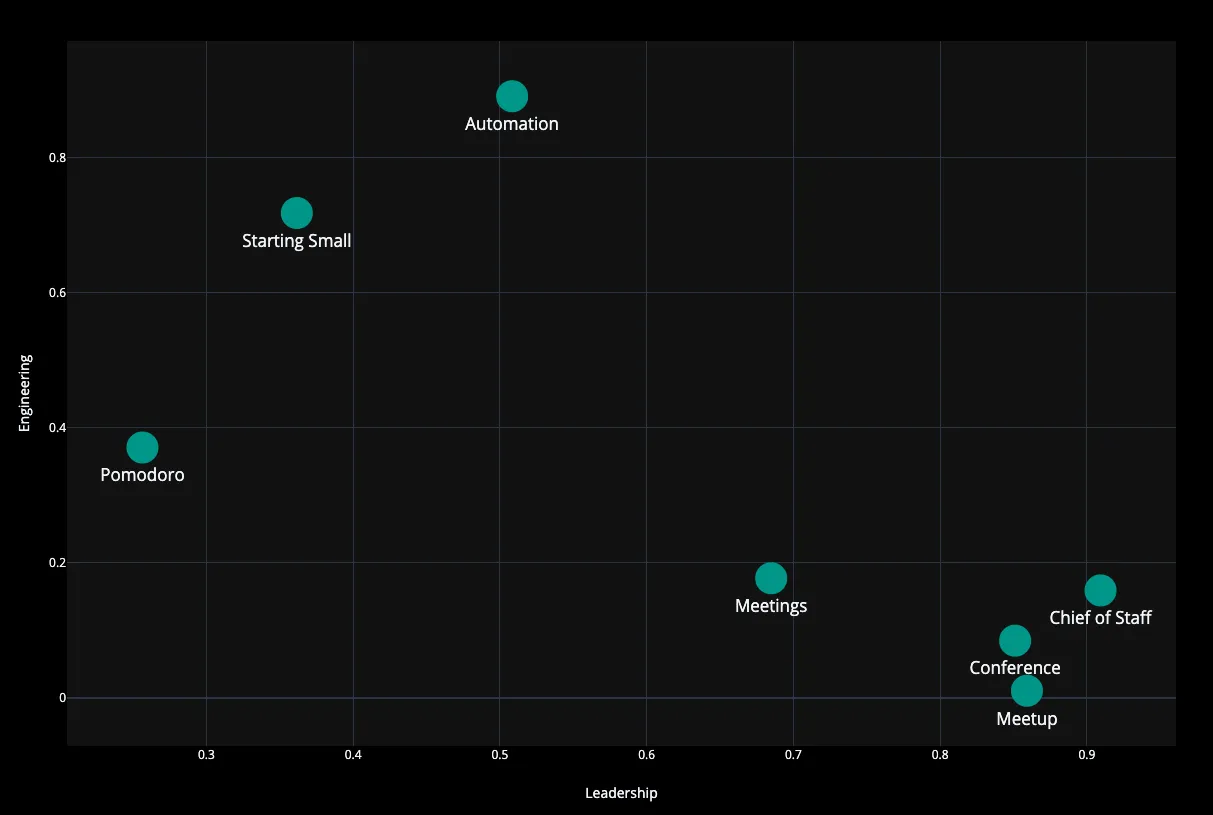
Comparing two topics doesn’t give us much. To get more accurate information, we can add a third axis. This one measures the relation to “productivity”. Since the axis needs to be orthogonal to the other two, we need to jump into the third dimension to visualize it.
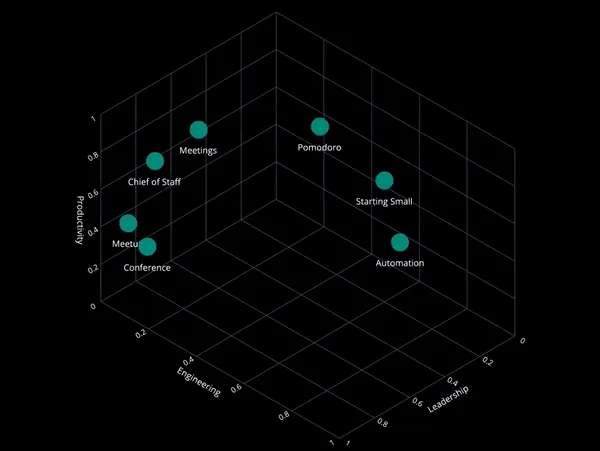
We can still get the distance between points, but now we’re comparing across three dimensions. OpenAI uses thousands of dimensions to create embeddings, but the concept is the same. The closer two nodes are, the more related they are.
This approach solves all our issues. We get more accurate, reliable, recommendations with one API call. Because of this, we can afford to send more data to make the recommendations better. Since this is no-longer chat based, the response is a structured data format. The embedding data may be different if we ran it again, but the data structure would be the same.
Sending the right data to the AI
We can send more data to the API, but which data do we send?
We could send the whole article, but we would soon hit the token limit.
Luckily, ChatGPT is great at summarizing and categorizing text.
We can use this to our advantage and ask it to generate tags for all our articles.
By sending tags instead of the full article, we send less data but still get the point of the article across.
Because I was only doing this once, I used the ChatGPT app.
This came with the added benefit of using the more powerful GPT4 engine that isn’t available to us on the API.
Here’s the prompt I wrote:
Given the following markdown article, please suggest five tags formatted as yaml:
{ARTICLE_CONTENT}
Notice I’m using the BDD test style again. I didn’t provide an example response, so the results weren’t reliable. Since this was using the ChatGPT app though, it didn’t matter too much. It had the context of the previous chat messages so I could refine the result. When it returned the results in the wrong format, I would ask it to, “reformat the response as yaml” and it fixed it up. I could also refine the suggestions by saying, “swap {TAG_NAME} for another suggestion”.
Here were the suggestions for this article:
- AI experimentation
- recommendation feature
- OpenAI API
- embeddings
- article tagging
It took a while to generate all the tags, but it was a one-time operation. Once I had all the tags, I wrote a script that fetched all the articles and extracted their tags. I then sent an array of these to the embedding endpoint and got all the data back to run comparisons against later.
{
input: [
"Experimenting with AI: AI experimentation, recommendation feature, OpenAI API, embeddings, article tagging",
"Increase your focus with pomodoro: Productivity, Time Management, Focus Technique, Pomodoro Technique, Distraction Management",
"Running a Conference: conference, event organization, sponsorship, diversity fund, speaker payment",
//…
]
}
Cosine similarity formula
Our brains can’t handle graphs in dimensions higher than the three we live in, but computers have no problem with it. Using the cosine similarity formula, we can get the distance between two points in any number of dimensions. Letting the compute-cosine-similarity npm package do the heavy-lifting, made computing similarity a breeze. To get the recommended articles, I loop through all the articles and calculate their similarity to the current article. Then I sort the array by similarity, remove the first result, and return the next three. This is all done against the dataset we generated previously, so it’s really fast.
Takeaways
This approach solved all the issues with the first POC. It’s much more reliable since we’re dealing with deterministic data. There’s only one API call that’s made once every few weeks. Most importantly, the recommendations are much better. They’re not perfect, but they’re good enough.
// For "Running a Conference"
{
"recommendations": [{
"title": "Starting a Meetup",
"path": "/wrote/starting-a-meetup/",
"similarity": 0.8543
},{
"title": "All Meetings are Optional",
"path": "/wrote/all-meetings-are-optional/",
"similarity": 0.8363
},{
"title": "Automate Your Meeting Agendas",
"path": "/wrote/automate-your-meeting-agendas/",
"similarity": 0.7954
}]
}
Recommendations are a nice feature, but the point of this was to learn more about AI. I’m an engineering manager so I don’t need to be a guru, but I still need to know what I’m talking about. By going through a practical application of AI, I’m better prepared for conversations with my engineers as we dive in to AI at GitLab.
If I’ve made any incorrect assumptions, or could have done this better, reach out on Mastodon, or Twitter and tell me about it. I’m always happy to learn.
Comments
(Powered by webmentions)Start the Conversation